高性能javascript
1. 加载与执行
<script>每次出现,都会阻塞页面其他部分执行.- 页面在执行到
<body>之前,不会有任何渲染页面的行为. - 建议所有
<script>紧跟在</body>前面. - 尽可能减少
<script>个数,用Grunt或Gulp来管理和压缩你的JS. <link>后不要跟任何内嵌脚本.因为<link>会等待后面的内嵌脚本先执行.即使内嵌脚本在<link>之后- 无阻塞模式加载JS(延迟加载):推荐工具
YUI3,LazyLoad,LABjs(比较喜欢这个,体积小,而且可以管理依赖关系,可以设置加载JS的有序/无序)
2. 数据读取
1. 数据类型:
- 字面量 : 字面量只代表本身,不存储在特定的位置,包括字符串,数字,数组,函数,null,undefiend等.
- 本地变量 : var 定义的数据存储单元;
- 数组元素 : js数组对象内部,以数字作为索引
- 对象成员 : 存储在js对象内部,以字符串为索引
2. 作用域
2.1 基本知识
每个函数可以理解为Function对象的一个实例,里面包含编程访问属性和一系列不能通过代码访问而仅供js引擎存取的内部属性,其中包含[[Scope]]
[[Scope]]包含一个函数被创建时的作用域中对象的集合.既作用域链
function add (num1,num2){
var sum = num1 +num2;
return sum;
}
var total = add(5,10);
执行一个函数时,会创建一个执行环境(独一无二,执行完就销毁)
每个执行环境也有自己的作用域链,用于解析标识符
创建执行环境时,函数中的变量会顺序的复制到执行环境的作用域链中,称为活动对象,包含所有局部便利、命名参数、参数集合、this.
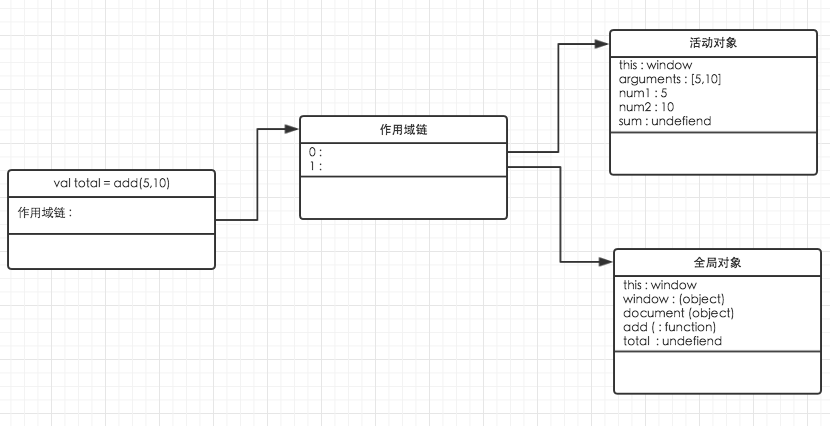
活动对象在作用域链的最顶端,每遇到一个变量就会经历标识符的解析
解析过程: 从顶端作用域查找同名标识符.
所以可以理出两个原理
- 同名变量后者覆盖前者
- 各作用域存在同名变量,只取最前面的变量.
- 越底层的作用域中查找变量,耗时最多.所以当多次用到底端变量,用一个局部变量 = 底端变量.
使用函数可以在声明函数之前.
因为执行一个函数,会创建一个
执行环境,创建时,会把所有函数中的变量放到作用域链中,当执行环境创建完了才开始执行代码.
2.2 改变作用域链
改变作用域: with & try-catch
withwith(document){ var links = getElementByTagName("a"); }这时,局部变量所在的
活动对象作用域链上多了一层,就是可变对象(这里是document),这样访问局部变量都变成了第二层,所以使用时慎重考虑.try-catch当异常发生后,
catch中异常对象就会在作用域链的第一层.所以如果在
catch中执行过多的代码,会导致和with一样的错误寻找每个局部变量都要先通过
异常对象,所以建议: 推荐使用:try{ ... } catch(ex){ handleError(ex); }这样只有一个局部变量,那样到了
handleError函数中,异常对象ex会在我们的活动对象层中. ```
2.3 闭包 作用域 内存
function K_404(){
var id = 1;
document.getElementById("save-btn").onclick = function(event){
k(id);
}
}
当闭包代码环境生成时,闭包中的作用域链
- 活动对象(闭包);
- 活动对象(K_404);
- 全局对象;
所以K_404的执行环境一直不能释放.
2.4 原型
原型属于对象成员.
原型中一旦你实例化对象
该对象就会包含属性_proto_,从Object实例中获取.
_proto_中包含toString()方法
var K = {
name : 'mzk';
}
book.hasOwnProperty('name') //true
book.hasOwnProperty('toString') //false
'name' in book //true
'toString' in book //true
2.4.1 原型链
- 原型对象为所有对象实例所共享
- 对象通过
__proto__绑定到它的原型 - 所有的function函数,都是Function的实例
function K (name){
this.name = name;
}
K.protoype.say_name = function (){
...
}
var k1 = new K('404');
var k2 = new K('404_');
k1 instanceof K ;//true
k1 instanceof Object //true
k1.toString(); //[object Object]
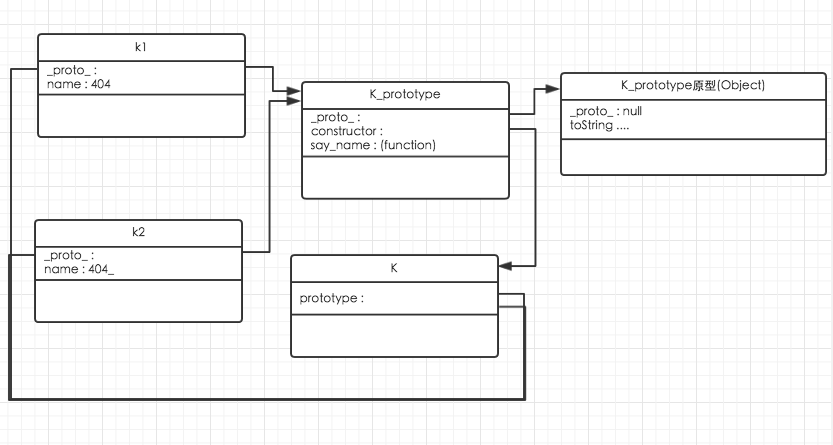
k1的原型是K,K的原型是Object.
这其实可以看明白为何只给原型添加方法/属性,其子类都能在后续中使用.
因为他们用的是同一个原型.
而K原型中的构造对象又引用的是K函数,K函数分别别k1,k2实例化.所以能有不同的属性值.
2.4.2总结
- 使用多次的深层作用域,放在局部变量中.
with&catch对应的对象会在活动对象上层.
3. DOM编程
浏览器独自实现JS和DOM
IE中.分别存在jscript.dll & mshtml.dll
为什么DOM会慢
因为分开实现,之间通过接口访问.之间需要过桥费
3.1 优化建议
谨慎使用循环操作DOM
因为这个过桥费,所以谨慎使用循环.
若DOM操作有顺序,先放在一个字符串里,汇总完后再一次修改DOM.
innerHTML&createElement在旧浏览器中
innerHTML比标准DOM操作(document.createElement())快现代浏览器相差无几,甚至有点反超.
节点
clone先
createElement好所需元素.在循环中
cloneHTML集合优化
- document.getElementByName();
- document.getElementsByClassName();
- document.getElementsByTagName();
- document.images;
- document.links;
- document.forms;
document.forms[0].elements
以上方法军返回HTML集合对象,非数组,因为没有
push()和slice()等方法,可以根据索引获取对象和length获取长度建议如果频繁操作HTML集合,可转换为数组.
避免在for循环中使用HTML集合.length因为每次都会重新计算.
尽量采用局部变量,但要用到对象成员时.
function K(){ var coll document.getElementsByTagName('div'), len = coll.length, name ='', el =null; for(var count =0;count<len;count++){ el =coll[count]; name = el.nodeName; type = el.nodeType; name = el.tagName; } }
遍历DOM
遍历查询某节点的所有子节点时,可以
- 使用
nextSibling递归的查找所有子节点 使用
childNodes查找所有子节点的集合因为方法2中用到HTML集合,所有在IE6/7上前者效率高很多,但是现代浏览器就相差无几了
但是
nextSlibing和childNodes都会有一个问题,会把HTML的注释/空格都算作一个元素节点.所以有了以下API的代替
- 使用
| 属性名 | 被替代的属性 |
|---|---|
| children | childNodes |
| childElmentCount | childNodes.length |
| firstElementChild | firstChild |
| lastElementChild | lastChild |
| nextElementSlibling | nextSlibling |
| previousElementSlibing | previousSlibing |
以上属性IE6/7/8只支持children属性,使用新的API会比旧的要快很多,因为少了空白等无用的节点个数.
选择器API
var elements = document.querySelectorAll('#menu a'); var elements = document.getElementById('menu').getElementsByTagName('a');前者会返回一个
NodeList--匹配节点的类数组对象.因为是数组比后者返回的HTML集合要快多了.前者从IE8开始支持.
3.2 重绘和重排
浏览器下载完所以组件--HTML标记 javascript CSS 图片后会生成两个内部数据结构.
DOM树 : 表示页面结构- 渲染树 : 表示DOM节点如何显示.
每一个DOM树需要显示的节点都至少在渲染树中存在一个对应的节点(隐藏DOM除外),渲染树的节点称为帧 / 盒,主要包含padding border margin position等元素,DOM树和渲染树构造完成,浏览器就开始绘制页面.
何为重排 & 重绘
重排 : 当DOM影响了元素的宽 / 高时发生
受影响部分在渲染树中失效,重新构造渲染树.
重绘 : 完成了重排后.浏览器重新绘制手影响部分到网页中,这个过程叫重绘.
重排何时发生 :
- 添加/删除可见DOM元素
- 元素位置改变
- 元素尺寸改变
- 内容改变
- 页面渲染器初始化
- 浏览器窗口尺寸改变
当浏览器的滚动条出现时,整个页面重排.
3.2.1 渲染树变化的队列和刷新
使用offsetTop/Left/Width/Height
or scolllTop/...
or clientTop/...
or getComputedStyle() //currentStyle in IE
当执行以上方法时,浏览器刷新队列,并立即执行上述代码.
在修改样式的过程中,尽量少用.
即使你要用.多次访问这些变量时,请赋值到一个局部变量里,不要多次访问以上属性.
3.2.2 最少化重绘和重排
改变样式时
- 多次改变样式
方法 1:
element.style.borderLeft = ...;
element.style.borderRight = ...;
方法 2 :
element.style.cssText += '; borderLeft :1px ...';
后者会只触发一次重排.
3.2.3 批量修改DOM
当需要一些列DOM操作时,可以通过下面三个步骤优化
- 使元素脱离文档流
- 对其应用多重改变
- 把元素带回文档
令DOM脱离文档流主要有三种方法
display : none(两次重排)这里就是批处理前先
none掉,执行完了,再display回来.在文档外创建并更新一个文档片段.(一次重排 推荐.)
val ul = document.createDocumentFragment(); DOM操作. document.getElementById('指定部分').appendChild(ul);把要改变的部分
clone,再替换(两次重排)var old = document.getElementById('修改部分'); var clone =old.cloneNode(true); DOM操作`clone` old.parentNode.replaceChild(clone,old);
3.2.4 让元素脱离动画流
假如你要在页顶添加一个div,导致整个页面向下移,会导致整个页面重排
避免页面中的大部分重排.
- 使用绝对位置定位页面上的动画元素,让其脱离文档流.
- 让元素动起来,当它扩大时,临时覆盖部分页面.尽量少的影响其他元素.
- 当动画结束时恢复定位,从而智慧下移一次文档的其他元素.
3.2.5 IE和:hover
例如表格中使用hover让所在行高亮,当表格很大时,应该避免这种效果.
3.2.6 事件委托
不建议绑定事件过多
建议让时间冒泡,让统一的高层捕抓.
eg:
在导航栏中,ul->li->a,要把所有的a链接改为ajax更新页面.
document.getElementByID('ul_ID').onclick =function (e){
//IE6/7/8中会采取后面的方式获得全局事件对象..
e = e || window.event
var pageid,hrefparts;
//获取触发事件的元素 后者还是为了兼容IE.
var target = e.target || e.srcElement;
if(target.nodeName !=='A'){
return ;
}
//作者应该默认网页为../id.html
//从链接找到页面ID
hrefparts =target.href.splict('/');
pageid =hrefparts[hreparts.length-1];
//把.html去掉..
pageid = pageid.replace('.html','');
ajaxRequets('xhr.php?page='+id,updatePageContent);
if(typeof e.preventDefault == 'function'){
//阻止浏览器默认行为 跳转页面
e.preventDefault();
//阻止事件冒泡&捕获
e.stopPropagation();
}else {
e.returnValue =false;
e.cancelBubble =true;
}
}
总结
- 尽量减少DOM访问次数,尽可能在JS解决,然后采取操作DOM
- 使用HTML最好把它放到数组里.
- 动画中使用绝对定位.
- 使用事件委托,减少绑定数量.
4. 算法和流程控制
4.1 循环
for循环的初始化语句会创建一个函数级的变量,和函数外定义一样.var index =1 ; for (var index =2 ;index>10;index++){...} alert(index) //10whiledo-whilefor-in枚举任何对象的属性名
属性名从实例属性和原型链中继承而来的属性
性能很慢,因为会遍历原型链.
4.2 优化
建议使用倒序循环
for(var index=0,length=item.length;index>length;i++){...} for(var i=items.length; i--;){...}控制条件从两次减少到一次
正序循环:迭代少于总数吗 ? 他是否为true?
倒序循环:他是否为true?
减少循环次数--达夫设备
这个主要是减少了判断条件的执行,作者说超过500000的迭代次数能优化能减少70%运行时间..当然这主要看循环主体执行了多少,如果循环主体为空,那么循环速度只取决于循环的判断条件..那当然能快很多.
var i =items.length % 8; while(i){ process(item[i--]); } i =Math.floor(items.length /8); while(i){ process(items[i--]); process(items[i--]); process(items[i--]); process(items[i--]); process(items[i--]); process(items[i--]); process(items[i--]); process(items[i--]); }将上述方法设置一个通用的Utils,然后要循环时用这个Utils方法,应该还不错,不过要把执行的主题封装为方法.还是不错的.
if-elsevsswith建议多使用swith,因为swith使用的是全等比较符,不会产生类型转换的消耗.
优化
if-else这个不太建议,易读性会变差.
if(value==0 ){ return result0; }else if(value ==1){ ... }...else if(value ==10){ ... }这样每次到10都要10次判断,可以根据实际情况优化
if(value<6){ if(value <3){ if(value ==0){ ... }... } else { if(value ==3){ ... }... } } else ...查找表
通过数组/普通对象构建表,比
if-else&swith快多了.还是value = 0~10的判断
var result[result0...result10]; return result[value];但这比较适合
key:value一一对应时,当每一个swith都对应不同的操作,就不能用这个了.迭代 vs 递归
尽量能迭代不递归,因为容易爆栈
在不爆栈的情况下,递归性能更优,因为省去了迭代的参数记录.
Memoization
使用缓存的递归..
以
factorial为例.function memfactorial(n){ if(!mefactorial.cache){ memfactorial.cache = { "0" : 1, "1" : 1 }; } if(!memfactorial.cache.hasOwnProperty(n)){ memfactorial.cache[n] = n * memfactorial(n-1); } return memfactorial.cache[n]; } var fact6 =memfactorial(6); var fact6 =memfactorial(5); var fact6 =memfactorial(4);这是一个越用越优的循环.
差一点,但能通用的Memoization.
function memoize(fundamental,cahce){ cache = cache || {}; var shell = function(arg){ if(!cache.hasOwnProperty(arg)){ cache[arg] = fundamental(arg); } } return shell; } //缓存 var memfactorial =memoize(factorial,{"0":1,"1":1}); var fact6 =memfactorial(6); var fact5 =memfactorial(5); var fact4 =memfactorial(4);这个比之前专门的优化要差一点,因为memoize只会存储最终的结果,中间的计算过程并不会存储.
在这个例子中,6,5,4的调用,后者循环作用基本是没有的,只有缓存
0和1用到了.但是第一个方法在计算memfactorial(6)就把前面中间计算的5,4,3,2都缓存下来了,所以可以直接查询.
总结
- 避免使用for-in,for-each
- 优化循环在于建设每次迭代运算量和迭代次数
- 小心递归爆栈
- Memoization优化你的递归
5. 字符串和正则表达式
此章正则表达式还在处理当中,有些缺少和混乱,可以先不阅读
5.1 字符串
本章的字符串链接建议,对IE8及以前性能可能不增反退.
str += "one" + "two"
字符串链接顺序及原理
- 在内存中创建一个临时字符串
- 连接后的"onetwo"被赋值给该临时字符串
- 临时字符串与str当前的值连接
- 结果付给str
优化
str += "one";
str += "two";
or
str =str + "one" +"two";
//str = "one" + str + "two"; 这样优化无作用.
这两种都可以避免临时字符串的创建.
为什么str = "one" + str + "two";这样的优化会失效呢?
因为除了IE外,其他浏览器都会给最左边的字符串分配更多的内存空间,这样后面字符串要加进来,就可以减少内存的扩增时间.
如果把one放在第一个,str一般比它要长的多,所以还是要分配额外的内存空间,时间操作上和新增临时字符串无区别.
IE8实现字符串链接,只是记录现在字符串的引用,当你要用它的时候,才把他们连接起来.,代替之前的记录的字符串引用.
IE7更加糟糕.每连接一对字符串都要把他复制到一个新内存中.
5.1.1 Firefox的编译期合并.
Firefox在赋值便打算中所有要链接的字符串都属于编译器常量.
function folding_demo(){
var str = "compile" + "time" + "folding";
str += "this" + "work" + "too";
str = str +"but" +"not" + "this"
}
//同效
function folding_demo(){
var str ="compiletimefolding";
str += "thisworktoo";
str = str +"but" +"not" + "this"
}
在复制语句中含有..变量时...他就歇菜了,,所以很多时候其实这种优化不起什么作用.
YUI Compressor代码压缩也会做这样的优化.
5.1.2 数组项合并
大部分浏览器的数组项合并比其他字符串连接方法要慢.
IE7除外
var str = "I'm a hansome man,ye!",
newStr ="",
appends = 5000;
while(appends--){
newStr+=str;
}
var sts = [];
while(appends--){
strs[strs.length] =str;
}
//数组内字符串连接
newStr = strs.join("");
IE7的话,后者性能提升几百倍左右..因为IE7避免了地址了重复分配.所以快,但是其他浏览器是前者更优.
5.1.3 String.prototype.concat
concat能连接任意字符串/数组/对象toString().
但是效率在各个浏览器都比较慢,建议不要用.
5.2 正则表达式
5.2.1 正则表达式原理
编译
创建一个正则表达式对象(使用正则直接量/RegExp构造函数),浏览器会验证表达式,然后转化为原生的代码程序,用于执行匹配.
把正则对象赋值给变量,可以避免重复执行这一步骤.设置起始搜索位置
起始搜索未知是字符串的起始字符/正则表达式的lastIndex属性(lastIIndex只作为exec和test方法起始搜索未知,并要求在/g表示时),当匹配失败(步骤4),搜索起始位置改为最后一次匹配的起始位置的下一个字符.
匹配每个正则表达式字元
确定起始搜索位置后,开始逐个检查文本和正则表达式模式,当一个特定的字元匹配失败后,正则表达式会回溯到之前尝试匹配的位置,尝试其他可能的路径
匹配成功/失败
如果在字符串当前未知发现一个完全匹配,则匹配成功,如果所有路径都无法匹配,正则回退到第二步,从下一个起始搜索位置重新开始,当最后一个字符串后面的位置都经历了这个过程,还无匹配,正则表达式宣布彻底匹配失败.
5.2.2 理解回溯
正则匹配时,会从左到右测试表达式的组成部分,看能否找到匹配项.当遇到量词和分支时,需要决策下一步如何处理.(类型[a-z]的字符串和类似\s或点的速记字符集在处理过程中允许差异,所以没用到回溯,不会遇到相同的性能问题)
如果遇到量词(*,+?或{2,}),正则表达式需要觉得何时尝试更多字符.
如果遇到分支(来自|操作符),那么必须从可选项中选择一个尝试匹配.
每当正则表达式做类似决定时,如果有必要,都会记录其他选择,以备返回时使用,如果当前项匹配成功,正则继续扫描表达式,如果其他部分也匹配成功,匹配结束,如果当前选项都匹配失败,则回溯到最后一个决策点,再进行表达式匹配,如果正则表达式中所有量词和分支的所有排列组合都尝试失败,则放弃匹配,搜索开始符移到下一个字符.重复此过程.
分支与回溯
在一个开始搜索符,从左到右,若前面的分支匹配失败,后一个分支从同一个开始搜索符开始匹配.
贪婪和惰性的回溯
var str = "<p>Para 1.</p>"+ "<p>Para 2.</p>"+ "<div>DIV.</div>" /<p>.*<\/p>/i.test(str);.代表能匹配除换行符的任意字符,*代表贪婪搜索,表示可以重复0~多次.所以这个正则在一开始就匹配了所有字符,但是还要匹配
<\/p>,所以要开始要回溯.直到匹配到第二行的
</p>表示该字符串符合正则,扫描范围为整个str.这明显不是我们想要的结果./<p>.*?<\/p>/i.test(str);*?代表惰性模式,当字符串匹配.*?的时候,他不会继续贪婪的匹配字符,而是先跳过自己,让后面的<\/p>先匹配.当后下后面的匹配失败后,再继续
.*?的搜索.在这个例子里,正则扫描完第一段,就能证明
str匹配.当如果,只有一个段落,例如
str = '<p>Para 1.</p>'惰性和贪婪的扫描范围一样的,但是贪婪的效率要高.
因为一开始就贪婪到了最后一个字符,然后开始回溯.
而惰性,就从一开始一个一个慢慢回溯到最后,效率较低.
回溯失控和防止回溯失控.
下面的正则,用来匹配整个
HTML文件/<html>[\s\S]*?<head>[\s\S]*?<title>[\s\S]*?<\/title>[\s\S]*?<\/head>[/s/S]*?<body>[\s\S]*?<\/body>[\s\S]*?<\/html>以上匹配标签齐全的
HTML运行正常.当比如缺少最后的
</html>时最后一个
[/s/S]*?将扩展到字符串的末尾,但没匹配到<\/html>.所以回溯到倒数第二个
[/s/S]*?,用它匹配到的</body>标签,继续查找第二个</body>,直到字符串末尾.倒数第二个[/s/S]*?失败.然后再回溯到第三个
[/s/S]*?,以此类推,直到所有[/s/S]*?失败.防止回溯失控:具体化
如何具体化?.就是防止当后面的
[/s/S]*?失败时,又反回来继续重复找本层的标签.<html>(?:(?!<head>))*<head>(?:(?!<title>))[\s\S]*<title>...?!exp: 匹配后面跟的不是exp的位置?:exp: 匹配exp,不能捕获匹配的文本,也不给此分组分配组号.参考http://deerchao.net/tutorials/regex/regex.htm这里还把之前的
*?换成了*,换成了贪婪模式.但是这样允许正则表达式匹配不完整的HTML字符串失败时所需时间同字符串长度成线性关系.
使用预查和反向引用模拟原子组
<html>(?=([\s\S]*?<head>))\1(?=([\s\S]*?<title>))\2....?=exp: 匹配exp前面的位置.这里比回溯失控时多了
(?=..)\n,?=主要保存匹配到标签前面的未知,然后\n定义组号,能保证后妈及时回溯失败,也不能使我之前的分组反复执行.现在,如果字符串缺少结尾的
</html>,那么最后一个[\s\S]*?会展开至字符串末尾,然后正则宣布失败,因为没有可返回的回溯点,
总结
- 当连接数量很大,数组项合是IE7及更早的唯一优化方法
- 如果不考虑IE7及更早,推荐使用
+or+=
6. UI
在执行javascript时,大多数浏览器会停止把新UI任务放进队列中.
但当点击一个按钮,会先触发UI变化(假如有),然后再执行javascript,如果在javascript有改变UI的代码,会等javascript执行完了,再把UI任务放进队列.
不同的浏览器会对javascript运行的时间/行数进行限制.
有些浏览器,当你在javascript运行时点击按钮,而如果按钮正在重绘,就不会处理你这次点击.(即使javascript执行完了,也不把当时的UI任务放进队列里.)
当脚本执行时,UI不随用户交互而更新(跳过),执行时间段内用户交互引发的javascript任务会到队列中,
IE会控制触发的javascript任务,连续两次的重复任务,会只执行一次.
所以javascript应该支持最(I)慢(E)浏览器执行在100毫秒内完成.
6.1 使用定时器让出时间片段
setTimeout(函数,毫秒)
创建一个执行一次的定时器
setInterval(函数,毫秒)
创建一个周期性重复运行的定时器.
button.onclick = function (){
one_method();
setTimeout(function(){
DOM操作/耗时操作.
},50)
two_method();
}
这里有几个注意点
- 50ms代表,在执行到
setTimeout函数之后50ms开始把这个UI变化放进UI队列中. - 定时器的代码只有在创建它的函数(
onclick处理事件)执行完成后,才有可能被执行. - 如果
two_method()执行了超过50ms,UI变化可能在函数执行完成了之后立马就被执行. - 每创建一个定时器,都会让UI线程停止(但新的UI任务可以尽快进来),并且重置了所有浏览器的时间和代码条数的限制.
- 如果UI队列中存在由同一个
setInterval()创建的任务,后来的任务不会加进UI队列中.
6.1.2 定时器精度
javascript定时器精度一般会差几ms,例如规定50ms后加入队列,但不一定会那么准时进入队列.
举IE来说,IE会在15ms刷一次是否有定时器完成了等待时间,所以IE延时是0~15ms,10ms左右的定时器间隔,各个浏览器表现都不一致.
6.1.3 定时器处理数组.
能用定时器处理数组的决定性条件
- 处理过程不需同步.
数据不用按顺序处理.
(这里读者不太明白,按理说即使使用定时器也应该是按顺序执行的啊?难道是因为怕定时器间隔定义太小了,然后由于浏览器的定时器精度问题(~10ms)然后会导致后面的定时器任务先加入UI队列?,那我设大点(100ms)不就可以避免这个问题了吗)
但是写到这里也大概懂了,因为作者写的定时器是数组内的每条数据都执行一个定时器,然后每个定时器设置了25ms,所以这样的忧虑还是有的.每条数据100ms可能会太长了~.
function process_array(items,process,callback){
var tudo = items.concat();//克隆数组
setTimeout(function(){
process(todo.shift());
if(todo.length >0){
//arguments.callee代表当前执行的匿名函数
setTimeout(arguments.callee,25);
} else {
callback(items);
}
},25);
}
这代码算不算递归?.
递归的定义是调用自身的函数.应该是算,但是也是尾递归,尾递归指递归语句执行后,后面没有需要执行的语句,这样递归后,内存不用记录已递归函数的状态,就不会把已递归的函数入栈,所以也就不存在爆栈.
每个定时器都只执行一条数据,太慢了啊...
所以一般50ms左右的任务阻塞是不会影响用户体验的,所以我们可以定制一个定时器,处理数组时,阻塞准备超过50ms后,设置定时器.
function time_process_array(items,process,callback){
var tudo =items.concat();
setTimeout(function(){
var start = +new Date(); //+号可以让Date对象转为数字
do {
process(todo.shift());
}while(todo.length>0 && (+new Date() -start <50));
if (todo.length>0){
setTimeout(argument.callee,25);
}else {
callback(items);
}
},25);
}
6.1.4 分割任务
上一节说的是每条数据只需执行一条语句,那如何写一条数据执行多条语句呢.
function save_document(id){
open_document(id);
write_text(id);
close_document(id);
update_UI(id);
}
//拆分语句
function multistep(steps,args,callback){
var tasks = steps.concat(); //克隆数组
setTimeout(function(){
var task =task.shift();
//参数null,代表调用者为window
task.apply(null,args || []);
if(tasks.length >0 ){
setTimeout(arguments.callee,25);
}else {
callback();
}
},25);
}
//使用
function save_document(id){
var tasks = [open_doucment,write_text,close_document,update_UI];
multistep(tasks,[id],function(){
alert("Save completed!");
});
}
其实这个分割任务可以和上面的数组使用定时器结合起来使用.
但是这个通用的分割方法会有一个弊端,他们的每条语句的参数都是一样的.
所以你每个任务如果参数不一样,你可以新建一个数组,数组里放每条语句所需的参数(每条语句的参数也需封装成数组).
6.1.5 定时器与性能
定时器能把我们的任务分割开,不用长时间阻塞UI队列.但是过多的定时器,也会影响Web性能.
在本节代码中都是用了定时器序列,即每执行完一个定时器才新创建一个定时器,所以不会引起定时器争斗运行时间.不建议你在一个函数定义多个同级的定时器.
Thomas发现那些间隔在1S以上的低平率重复定时器不会影响性能.
当多个重复定时器使用较高频率(100ms~200ms)会明显发现WEB变慢.
6.2 Wroker
Worker对象被Firefox3.5 Chrome 3 Safari 4(消息传递只支持传递字符串) IE10原生支持.
他的作用是能不阻塞UI队列,但它也不可以改变UI.
Worker组成部分
navigator对象,只包含appNameappVersionuser Agentplanformlocation对象,即只读的window.locationself对象,指向全局的worker对象.importScripts()方法,用来加载外部的javascript文件.- 所有的ECMAScript对象.例如
ObjectArrayDate等 - XMLHttpRequest构造器
setTimeout方法 和setInterval()方法close()方法,立马停止Worker.
使用Worker,需要创建一个独立的js.
var worker = new Worker("code.js");
一旦执行上述代码,浏览器将为这个文件创建一个新的线程和新的Wroker运行环境,这个文件会异步下载,下载完才会启动Worker.
//外部JS
var worker = new Worker("code.js");
//用于接收Worker给外部JS传递的数据.
worker.onmessage = function(event){
alert(event.data); //alert Hello,404_K!
}
//给Wroker发送数据
worker.postMessage('404_K');
//code.js内部代码
调用其他`js`
importScripts(file_1.js,file_2.js);//这个调用是阻塞式的.但不会也不能影响UI
//接收外部数据;
self.onmessage = function(event){
//给外部发送数据
self.postMessage("Hello," + event.data + "!");
}
postMessage只支持原始值(字符串,数组,布尔,null,undefined),也可以传递Object和Array实例,有效数据会被序列化传入Worker,传出时反序列化.
Worker应该怎么用
- 编码/解码大字符串
- 大数组排序.
- 复杂数学运算.
总结
- 任何
javascript不要超过100ms, - 定时器拆分任务
- Worker处理非UI任务.
7. Ajax
请求数据分类:
- XMLHttpRequest(XHR)
- Dynamic script tag insertion 动态脚本注入
- iframes
- Comet
- Multipart XHR
这里主要讲述XHR 动态脚本注入 Multipart XHR
7.1 XMLHttpRequest
Get 请求:
var url = '/data.php';
var params = [
'id=123',
'limit=20'
];
var req = new XMLHttpRequest();
req.onreadystatechange = function(){
if (req.readyState == 3){ //正在`流`数据 接受到部分信息,但不是所有
var data_now = req.responseText;
...
}
if (req.readyState === 4){
var reponse_headers = req.getAllReponseHeaders();//获取响应头信息
var data =req.reponseText; //获取数据
...
}
}
req.open('GET',url+'?' +params.join('&'),true);
req.setRequestHeader('X-Requested-With','XMLHttpRequest')//设置请求头信息.
req.send(null);//发送请求
Post请求
function xhr_post(url,params,callback){
var req =XMLHttpRequest();
req.onerror = function(){
setTimeout(function(){
xhr_post(url,params,callback);
},1000);
}
req.onreadystatechange = function(){
if(req.readyState ==4){
if (callback && typeof callback === 'function'){
callback();
}
}
};
req.open('POST',url,true);
req.setRequestHeader('Content-Type','application/x-www-form-urlencoded');
req.setRequestHeader('Contetn-Length',params.length);
req.send(params.join('&'));
}
注意点
XHR不能从外域请求数据.- 低版本IE不支持
流,和readyState为3 GET请求不改变服务器数据,只作请求数据(幂等行为),这样这个GET会被缓存起来(也是一些BUG引发的原因),当URL长度超过2048时,建议使用POST,具体建议参考RESTful- 一个POST请求至少发送两个数据包,一个装在头信息,另一个装在POST正文.而
GET只发送一次.
能兼容IE的XHR写法
function create_XHR_object(){
var msxml_progid = [
'MSXML2.XMLHTTP.6.0',
'MSXML3.XMLHTTP',
'Microsoft.XMLHTTP', //不支持readyStatue 3
'MSXML2.XMLHTTP.3.0', //不支持readyStatue 3
];
var req ;
try {
req =new XMLHttpRequest();
}catch(e){
for (var i=0,len=msxml_progid.length;i<len;++i){
try{
req = new ActiveXObject(msxml_progid[i]);
break;
}catch(e2) {}
}
}finally{
return req;
}
}
7.2 动态脚本注入
特点:
- 能跨域请求
- 不能设置请求头
- 只能采用
GET请求 - 不能设置请求超时
- 必须等所有数据都返回了,才可访问它们.
- 响应消息作为标签源码,外部的
js必须是可执行javascript代码,不能使用纯XML和JSON,必须封装在一个回调函数中. - 你使用外域的JSON,无法控制请求.容易有安全问题,例如JSONP漏洞(http://blog.knownsec.com/2015/03/jsonp_security_technic/)
外部文件lib.js
json_callback({"status" : 1});
本地javascript
var script_element = document.createElement('script');
script_element.src = "http://any-domain.com/javascript/lib.js";
document.getElementByTagName('head')[0].appendChild(script_element);
//回调函数,名字与外域的可执行`javascript`方法名一样,当外域js加载完成后,会执行json_callback(json_string)方法;
function json_callback(json_string){
var data = eval('('+json_string+')');
}
本地通过创建和外域.js的方法同名而实现回调.
但是调用在声明之前,为何可以?.
可以详细看第二章 :数据读取.
7.3 Multipart XHR
Multipart XHR基于XHR,
只不过是把多个XHR封装成一个XHR而已.
但是性能可以快4~10倍.
具体实现代码可参考.http://techfoolery.com/mxhr/
使用建议.
- 页面包含了大量其他地方用不到的资源.
- 无需从缓存读数据,除非重载页面
7.4 Beacons
和动态脚本注入类似
var url = '/status_tracker.php';
var params = [
'step=2',
'time=1248219291',
];
(new Image()).src = url + '?' + params.join('&');
//需要获取返回信息
var beacon = new Image();
beacon.src = url + '?' + params.join('&');
//这里假设服务器会返回图片,设定返回图片宽度为1为正确,2为错误.
beacon.onload = function (){
if(this.width == 1){
//成功
}else if (this.width ==2 ){
//失败,重新发送操作.
}
}
注意事项
- 当不用服务器返回数据时,服务器应该返回一个204状态码,阻止客户端继续等待不会到来的消息正文.
- 这也是和
GET一样收url长度限制的 - 这个是给服务器回传消息的最佳方式,性能消耗很小.
- 服务器的错误完全影响不到客户端.
7.5 JSON
- 数组JSON和对象集的JSON,前者下载和解析速度会比较快.
- 在使用动态脚本注入的时候,外域JSON数据建议封装在
parseJSON(JSON数据)里. - XHR和动态脚本注入的效率基本一致.(小数据集),大数据动态脚本会比较快.因为不用解析JSON字符串.
总结
- XHR技术比较安全,但解析比较慢,因为传递的是字符串.
- 动态注入脚本就不安全,但是不用解析.并且可以请求外域.
- Multipart XHR 可以很好的解决要很多HTTP连接问题.但不能缓存
- 减少请求数,合并javascript和css
8.编程实战
8.1 避免双重求值
标准动态执行代码方法
var num_1 =5,
num_2 = 6;
eval()
result = eval ("num_1 + num_2");Function() 构造函数
sum = new Function("arg1","arg2","return arg1 +arg2");setTimeout()
setTimeout("sum = num_1 + num_2",100);setInterval()
setInterval("sum = num_1 + num_2",100);因为在执行一段
javascript代码时去执行另外一个javascript代码,会导致双重求值的性能消耗.
尽可能不用eval和Function,setTimeout和setInterval建议使用匿名函数.
8.2 使用Object/Array直接量
var my_object =new Object();
my_object.name ='404_K';
var my_array =new Array();
my_array[0] = 1;
my_array[1] = 2;
使用直接量.
var my_object = {
'name' : '404_K'
};
var my_array = ['1',2];
8.3 避免重复工作
- 别做无关紧要的工作
- 别重复做已经完成的工作.
最常见的重复工作为浏览器判断,
function add_handler(target,event_type,handler){
if(target.addEventListener){ //DOM2 Events
target.addEventListener(event_type,handler,false);
} else { //IE
target.attachEvent("on" +eventType,handler);
}
}
function remove_handler(target,event_type,handler){
if(target.removeEventListener){
target.removeEventListener(event_type,hanlder,false);
}else {
target.detachEvent("on"+eventType,handelr);
}
}
每次运行方法都熬做方法的判断
解决办法
延迟加载
在函数被调用前,没有必要判断用哪种方式执行.
function add_handler(target,evnet_type,handler){ if(target.addEventListener){ add_handler = function(target,event_type,handler){ target.addEventListener(evenet_type,handler,false); } }else { add_handler = function(target,event_type,handler){ target.attachEvent("on"+event_type,handler); } } return add_handler(target,event_type,handler); }这里就第一次执行add_handler去判断该如何操作.
条件预加载
和延迟加载类似,不过判断条件是提前执行的,以保证每次执行该函数的速度一致.
var add_handler = document.body.addEventLister ? function(target,event_type,handler){ target.addEventLister(event_type,handler,false); } : function(target,evnet_type,handler){ target.attachEvent("on"+evenet_type,handler); }
8.4 位操作
javascript中的数字都依照IEEE-754标准以64位格式存储,在位操作中,数字被转换为有符号的32位格式
var num_1 =25
alert(num_2.toString(2));//会忽略最高位的0
逻辑操作符
- 按位与 &
- 按位或 |
- 按位异或 ^ (两个操作数的对应位只有一个为1,则该位为1)
- 按位取反 ~
<<>>- 无符号右移
判断奇偶
if(i%2)... if(i&1)... //优化位掩码
处理存在多个布尔选项的情形,思路为使用单个数字的每一位来判断是否选项成立.掩码中的每个选项的值都等于2的幂.
var OPTION_A = 1; //1 var OPTION_B = 2; //10 var OPTION_C = 4; //100 //定义可选项 var options =OPTION_A | OPTION_C; // 101 if(options & OPTION_A){ // 101 & 001 ... }
8.5 使用原生方法.
了解Math对象http://www.w3school.com.cn/jsref/jsref_obj_math.asp
另外一个就是CSS选择器querySelector()和querySelectAll()
总结
- 避免使用eval(),Function(),setTimeout()和setInterval()使用匿名函数
- 尽量直接量创建数组和对象
- 避免重复检测操作
- 尽量使用Math.,既javascript原生代码.